11月,谷歌宣布它正在着手一项计划,最终将开发一种能够识别和翻译世界上使用最广泛的1,000种语言的机器学习模型。在过去的几个月里,该公司一直在朝着这个目标努力,并由从事该项目的团队成员发布了一篇博客文章。谷歌团队还发表了一篇论文,描述了在arXiv预打印服务器上引入其通用语音模型(USM)。
谷歌提供的更新是一个更重要目标的一部分:使用自动语音识别(ASR)创建一个能够按需翻译世界上任何语言的语言翻译器。为此,他们选择暂时限制他们试图支持的语言数量(100种),因为说不太常见语言的人数很少。这种稀有语言缺乏用于训练的数据集。
作为其公告的一部分,谷歌概述了他们的USM的第一步——将其分解为经过数十亿小时录制语音训练并涵盖300多种语言的语音模型系列。他们指出,他们的USM目前已用于YouTube上的隐藏式字幕语言翻译。他们还概述了每个系列的通用模型。
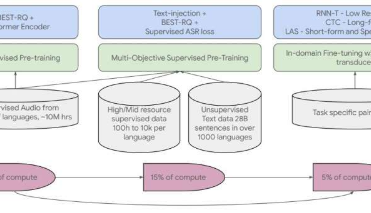
谷歌解释说,这些模型是使用涉及三种数据集的训练“管道”生成的:未配对的音频、未配对的文本和配对的ASR数据。他们还指出,他们正在使用conformer模型来处理项目所需的预期2B参数,并将使用三个主要步骤来实现:无监督预训练、多目标监督预训练和监督ASR训练。最终结果将生成两种类型的模型——预训练模型和ASR模型。
谷歌进一步声称,在目前的状态下,其USM已显示出与Whisper模型相当或更优的性能——Whisper模型是GitHub社区创建的通用语音识别模型。除了将USM用于YouTube之外,谷歌还有望将其模型与其他人工智能应用程序配对,包括增强现实设备。