在文本到图像模型中输入几个单词,您最终会得到一张异常准确、完全独特的图片。虽然这个工具用起来很有趣,但它也开辟了创意应用和探索的途径,并为视觉艺术家和动画师提供了工作流程增强工具。对于音乐家、声音设计师和其他音频专业人士来说,文本到音频模型也能起到同样的作用。
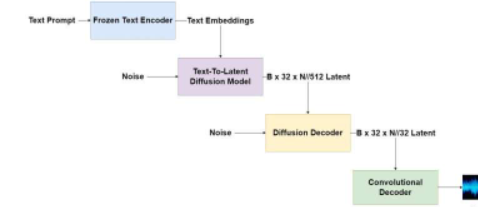
作为美国声学学会第 183 届会议的一部分,Stability AI 的 Zach Evans 在他的演讲“联合文本嵌入生成的音乐音频样本”中介绍了为此取得的进展。
“文本到图像模型使用深度神经网络,根据学习到的与文本说明的语义相关性,生成新颖的原始图像,”埃文斯说。“在对大量不同的带字幕图像的数据集进行训练时,它们可用于创建几乎任何可以描述的图像,以及修改用户提供的图像。”
文本到音频模型也可以做同样的事情,但最终结果是音乐。在其他应用中,它可用于创建视频游戏的音效或音乐制作的样本。
但是训练这些深度学习模型比图像模型更难。
“训练文本到音频模型的主要困难之一是找到足够大的文本对齐音频数据集进行训练,”埃文斯说。“在语音数据之外,可用于文本对齐音频的研究数据集往往比可用于文本对齐图像的数据集小得多。”
Evans 和他的团队,包括贝尔蒙特大学的 Scott Hawley,已经在从文本生成连贯且相关的音乐和声音方面取得了早期成功。他们采用数据压缩方法生成音频,减少了训练时间并提高了输出质量。
研究人员计划扩展到更大的数据集,并将他们的模型作为开源选项发布,供其他研究人员、开发人员和音频专业人员使用和改进。